
基于H.323高性能MCU的设计与实现
摘要:针对基于H.323协议的Openh323开源视频会议系统中源MCU容纳终端有限,图像质量差等缺陷,在VC++6.0开发平台上,采用基于帧缓冲映射软交换技术改进源码中的MCU,提高其存储转发的能力,从而增加参与视频会议的终端;在占用较少CPU资源的同时,有效提高其传输速率,并缩短了传输时延,取得了良好的测试结果。
Abstract:
Key words :
摘要:针对基于
H.323协议的Openh323开源视频会议系统中源
MCU容纳终端有限,图像质量差等缺陷,在VC++6.0开发平台上,采用基于帧缓冲映射软交换技术改进源码中的MCU,提高其存储转发的能力,从而增加参与视频会议的终端;在占用较少CPU资源的同时,有效提高其传输速率,并缩短了传输时延,取得了良好的测试结果。
随着计算机的硬件,特别是CPU主频的不断提升,基于软件的音、视频编码效率也越来越高,因此考虑到成本与各方面的因素,软件MCU必然成为以后的主流方向。但现今大多的MCU都是软硬件相结合,纯软件的MCU很少且效率不高。
当前H.323视频会议系统大都是以Openh323协议库为基础开发的视频和语音传输系统软件。Openh323是由澳大利亚Equivalence Pty Ltd.公司组织开发的,能实现基本的H.323协议框架,在Openh323 V4中,基于视频缓存池的MCU最多只能处理合成4路终端,不能适应现今市场发展的需要,因此重新设计MCU的架构,便成为研发软件MCU的关键。
l 源MCU的缺陷和不足
(1)OpenH323中源MCU只能形成不超过4个终端画面的图像。其中,4×1为CIF格式(352×288);l×1为QCIF格式(176×144),因此视频混合存在两种不同方式,包括QCIF格式源图像混合成CIF格式图像以及CIF格式源图像混合成CIF格式图像,如图1所示。
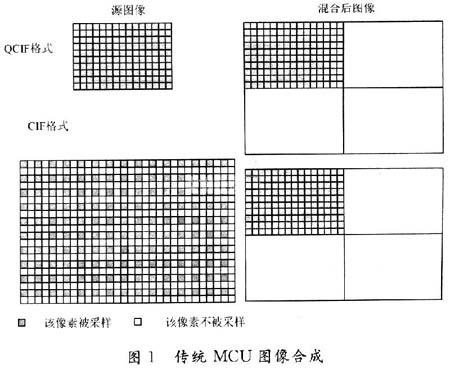
当源图像为QCIF格式时,源图像大小正好是混合后图像大小的1/4,这时可以将源图像整幅地拷贝到混合图像的相应位置;当源图像为CIF格式时,源图像与混合后图像的大小一样,因此源图像3/4的像素必须被丢掉,采用的方法是:对源图像在水平方向进行隔点采样,在垂直方向进行隔行采样。这样处理之后,源图像大小也正好是混合后图像大小的1/4,虽然图像的分辨率已经下降,但是保持了源图像画面的完整性;如果将MCU变成可容纳16个终端的显示画面,在将QCIF源图像转换为CIF的合成图像过程中,只能将源图像的采样点按倍数减少。也就是将CIF格式等分为16份,相当于用88×72的像素点去存储176×144 QCIF图像,合成图像显示的像素点只有源图像的1/4;如果将MCU可容纳的终端数目扩大为32,甚至更多时,图像的清晰度将大打折扣。
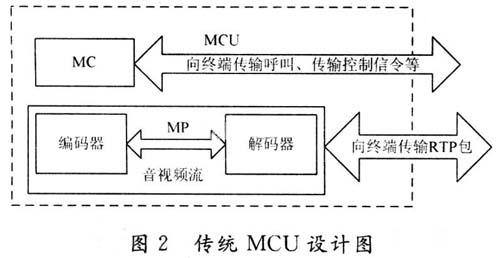
(2)传统软件MCU的架构是从硬件MCU继承过来的,MCU包括MC和MP部分。MC部分对终端进行连接控制以及逻辑通道的管理;MP部分对音频进行混合,视频进行合成。传统MCU的设计如图2所示,这种架构适用于硬件MCU;但对用软件实现的MCU并不太适合。用软件实现的MCU的编解码都是通过CPU来运算的,这样必然增加CPU的运算负荷。例如:要编码一路30 f/s的CIF(352×288)图像,大概编码后的字节数为30×352×288×2=6 MB,CPU要处理如此大的视频数据量,经测试,P4-2.6 G的CPU在这种架构下,最多支持5路终端,如超过5路,CPU运算负荷过大,其资源基本耗尽,图像合成的效果严重下降。
因此,要实现高性能的MCU,必须把MCU对多路音、视频编码的大数据量处理的工作环节转移到各个终端上,让终端对相应的音、视频编码进行处理,而MCU只对各路的音视频流进行存储转发,这样才能减轻MCU的负荷,从而提高系统的整体效率。
2 帧缓冲映射的软交换模式的MCU的设计
综上所述,在此提出采用基于帧缓冲映射软交换的 MCU系统设计模式,所谓的软交换模式就是仿照交换机的模式,不对音、视频流进行编解码的处理,只对数据进行转发与控制。
该MCU也包括MC与MP。基于软交换的MP,通过帧缓冲映射算法,查找终端对应的缓冲区,然后到把接收到的音、视频流存放到该缓冲区里面,通过MC控制,把音、视频数据流转发到终端。
2.1 MC部分总体设计思想
MC部分的设计主要包括会议组管理、会议RTP流转发管理。
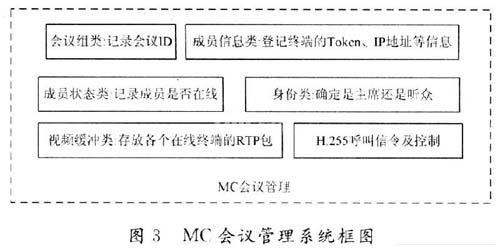
(1)会议管理。该系统只默认一组会议,且默认的会议房间为“rooml01”。对一组会议来说,主要管理会议的成员信息,处理与会者的加入与退出等。为了实现这些功能,建立一个会议组类、成员信息类、成员状态类、成员身份类和成员视频缓冲类。会议组类主要记录终端所选的会议ID;成员信息类主要记录终端的Token,IP地址等信息;成员类状态主要记录成员是否在线;成员身份类可以确定是主席,还是听众;成员视频缓冲类主要是存放在线各个终端的RTP包,一个缓冲类里面可以存在多个缓冲区。MC首先通过设定TCP特定的端口,并在端口上建立一个TCP*线程,终端通过这个端口与MCU进行TCP连接,并由MC建立一个H.225呼叫线程,用于*H.225呼叫信令,通过这个H.225通道,终端把自己的会议组ID,IP,Token等身份认证注册到MC。
图3为MC的会议管理系统框图。
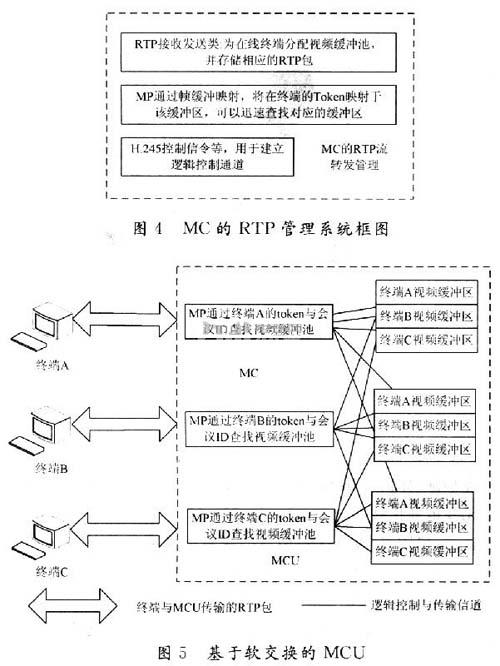
(2)会议RTP流转发管理。MCU对登陆终端进行注册后,MC建立一个H.245控制信令线程,并与该终端进行连接控制,通过H.245控制信令与Mc进行呼叫、信令处理与能力协商、主从决定;然后建立音、视频的接收逻辑通道,通过RTP接收类开始接收终端发送的RTP帧。把RTP帧保存到分配给该终端缓存区里。MC为已经进行了呼叫连接的终端分配了一一对应的视频缓冲接收区.该缓冲区是一个分配在堆里面的数据结构,例如:在终端A的在线人员列表上,可以看到登陆注册到MCU的人员名单;通过对终端的人员名单的选择,例如选择B,那么终端A可以要求MC转发终端B的音、视频,当MC收到终端A提交的要求转发终端B的信息后,在MC的A终端缓冲池里面,为终端B新建一个缓冲区,通过MP对终端B的Token的帧缓冲映射查找到终端B的音视频缓冲池,并在终端A与终端B之间建立一条逻辑通道,用于向终端A传输终端B的RTP包,当MC的终端A缓冲类接收到终端B的RTP包后,把RTP包拷贝到原来的接收缓冲区里;然后同样把终端B的惟一Token通过哈希函数映射到这个缓冲区上。
图4为MC的RTP管理系统框图。MC的软交换模式如图5所示。
2.2 MP部分总体设计思想
基于软交换的MP,通过帧缓冲映射算法查找终端对应的缓冲区,然后把接收到的音、视频流存放到该缓冲区里面,通过MC的控制,把音、视频数据流转发到终端。由于MCU需要处理大量的实时RTP包,效率成为了最主要的问题。因此如何从缓冲区里面快速搜索相应的数据包是MP能否快速处理数据的关键。考虑到MP要处理不同的终端,不同的终端对应不同的缓冲区,所以采用哈希函数映射法,它将任意长度的二进制值映射为固定长度的较小二进制值,并把这个哈希表存放到相应的内存区,以便多次的查找,这样通过这个较小的二进制值就可以以非常快的速度找到比较大的数值。因此把视频缓冲区的首地址存放到一个哈希表里面,并通过这个哈希表把终端的Token映射于这个缓冲区,这样通过终端的惟一TOken便可以迅速找到其对应的缓冲区。
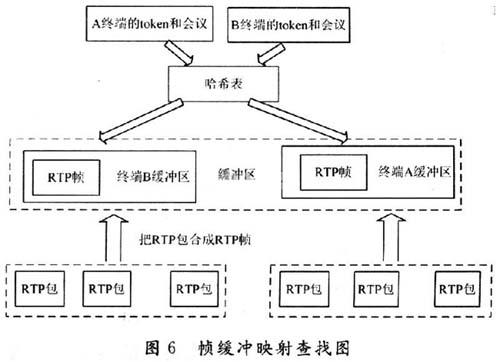
实现MP部分帧缓冲映射算法的具体设计步骤是:首先MCU把登陆的在线终端Token(终端的惟一标识)与会议ID默认为roomlol,通过哈希函数,映射到一个缓冲区,通过终端的Token和会议ID,就可以直接找到本终端的缓冲区,当MP收到终端的RTP包后,通过RTP包的边界分析,把多个RTP合成一个数据帧,然后把数据帧放到相应的终端缓冲区里面。帧缓冲映射的查找如图6所示。假设当终端A要求转发终端B的音、视频数据流时,MP通过哈希函数找到相应终端B的缓冲区域,然后把该缓冲区的数据读出到数据帧里面,最后通过RTP包进行发送到终端A,而终端A在接收到MCU发送的终端B的音视频数据压缩包后,再对其进行音视频进行解码。
2.3 MCU系统实现
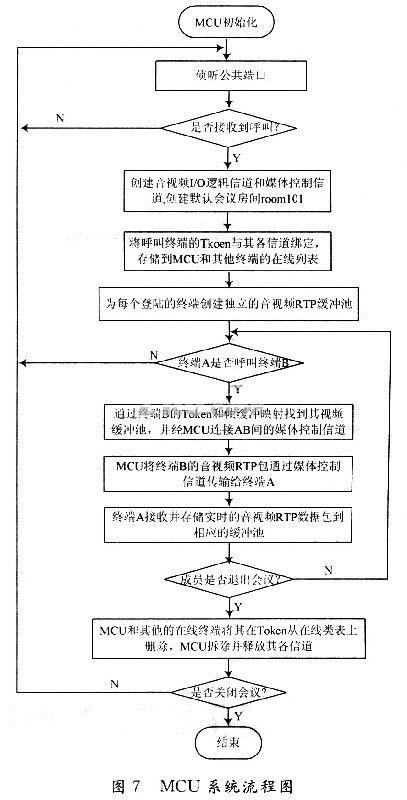
根据以上的设计思想,得出如图7所示的MCU系统流程图。
2.4 测试结果与结论
通过重新设计MCU的MC和MP后,MCU的性能有了较大的提高。从性能方面进行测试,由于传统的MCU在MC上进行编解码,只能容纳4路音、视频终端,而通过修改的MCU,MC没有进行编解码,只对音、视频进行存储转发,因此在9路音、视频的情况下,系统的CPU只占有5%。从效率、质量方面进行比较,由于传统的MCU进行了4路编解码,返回到终端的数据包延迟比较大,而修改过的MCU没有进行到编解码,因此数据包的延时很小。传统的MCU在MC里面进行图像的混合,图像的分辨率变为原来的1/4,因此图像质量有较大的下降,而基于软交换的MCU保持了原来图像的分辨率,因此图像质量较好。从视频的帧数来比较,传统的MCU架构不能达到15 f/s,而基于软交换的MCU能达到30 f/s。由于基于软交换的MCU的视频传输的是原来图像的分辨率,因此传输率比传统的MCU要高,但可以通过在终端采用传输率较低的编码器来降低传输率。表1为MCU改进前与改进后的对比。
终端的6分界面如图8所示。
3 结语
从以上的测试证明,基于软交换的MCU架构,使MCU的性能有了很大的提高。本文同时也说明了只要系统程序设计合理,基于软件的MCU是切实可行的。随着硬件水平的不断提高,纯软件的MCU将以其低成本、简易操作而普及到低端用户。
此内容为AET网站原创,未经授权禁止转载。