Tegra X1架构分析:CPU这是咋回事儿?
2015-01-07
来源:新浪手机
本文转自驱动之家
过去每一年开头的CES大展上,NVIDIA都会带来新一代的Tegra移动处理器。尽管过去两代表现一般,但是黄仁勋还是亲自登台,推出了全新的Tegra X1。

【GPU:强大的麦克斯韦】
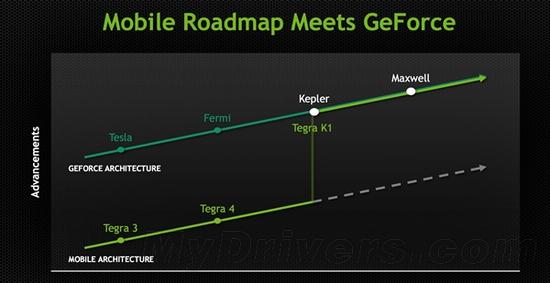
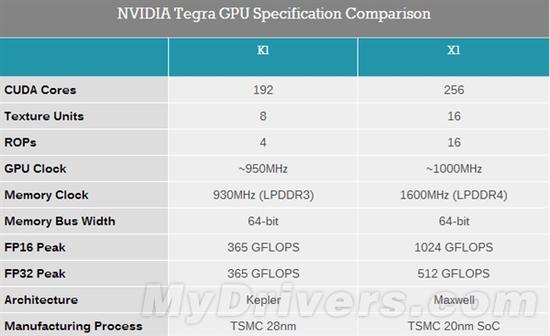
首先,NVIDIA是一家GPU公司,因此无论在桌面还是移动市场上,都对GPU异常重视。去年的Tegra K1首次引入了与桌面平级的开普勒架构,192个流处理器带来了惊人性能。今年的Tegra X1则进一步升级为麦克斯韦架构,流处理器也增至256个。
换句话说,去年用的是一组阵列(SMX),今年则是两组(SMM)!随之而来的是,纹理单元、ROP单元也都大大增强了,均有16个,尤其后者翻了两番,对于驱动4K 60Hz显示有很大好处。
从初步测试结果看,Tegra X1 GPU性能依然彪悍,可以轻松搞定苹果A8X里八核的PowerVR GXA6850。

在时间上,开普勒诞生了将近两年才走入移动平台,麦克斯韦架构只用了一年。更确切地说,Tegra X1用的是第二代麦克斯韦架构,而它在桌面上才出现了一个季度多点而已。
这也说明,NVIDIA的新架构从一开始就为移动平台进行了同步优化,所以我们才屡次看到麦克斯韦的能效是那么高,功耗是那么低。
新架构的诸多图形技术也被带了过来,包括更高效的CUDA核心、更简练的SMM阵列、第三代Delta色彩压缩、保守光栅化算法、体积区块资源(DX11.2)、多帧抗锯齿(MFAA)等等。
更重要的是内存带宽,这一直是限制移动SoC的瓶颈,传统方法就是增加位宽,但会大大提高复杂度和成本。
Tegra X1还是停留在64-bit位宽,但是大大增强了内存压缩,包括刚才说的第三代Delta色彩压缩,以及新的端到端压缩。再辅以新的LPDDR4(频率可达1600MHz),内存带宽基本不是问题。
然后值得一提的就是半精度FP16的支持,NVIDIA称之为“双倍速FP16”(Double Speed FP16)。
和开普勒一样,麦克斯韦架构也只有专门的单精度FP32、双精度FP64 CUDA核心,并没有给FP16分配独立资源,只是在操作方式上做了改变。
Tegra K1 FP16操作会被给予和FP32相同的待遇,每一个都交给FP32 CUDA核心处理。Tegra X1上如果条件允许,则会将两个FP16合并成一个Vec2,交给单独一个FP32 CUDA核心去处理。
这里的前提是两个FP16操作属于同一类型,比如都是加法或者乘法,甚至是乘加运算(FMA)。
所以说,NVIDIA宣称的原生支持FP16并不完全准确,只不过耍了个花招而已,比对手还是差一些。ARM Mali、Imagination PowerVR都有独立的FP16单元,AMD GCN 1.2版也会引入。
FP16在安卓的显示合成里使用非常多,游戏里也能看到,但更重要的是,它还能参与图形计算,比如图像识别什么的,比如Drive PX车载平台里就需要它。

具体频率还是没有公布,而按照NVIDIA说的1TFlops FP16浮点性能,那么应该是1GHz(1GHz×2FP16×2FMA×256=1TFlops),比去年略微高了一些。
FP32单精度浮点性能为512GFlops,比去年提高了40%。
 【CPU:为啥不用自主架构?】
【CPU:为啥不用自主架构?】
Tegra K1去年先是使用公版的四核A15,然后终于用上了NVIDIA自己苦心研发多年的64位自主架构“丹佛”,按理说今年只能是丹佛的增强版,甚至上四核,但结果却是四核A57加四核A53这种大路货。
究竟发生了什么?可以从路线图的变更上揣测一番。
Tegra K1的开发代号是“Logan”,金刚狼洛根,它之后本来应该说是“Parker”,另一位超级英雄蜘蛛侠帕克,说是会有丹佛架构CPU、麦克斯韦架构GPU、(16nm)FinFET制造工艺。
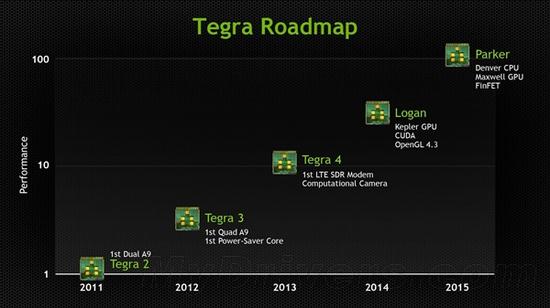
但去年3月底的时候,NVIDIA将其改成了“Erista”,金刚狼的儿子,而且只标注了麦克斯韦GPU架构,CPU和工艺根本不提。
如此一来就很好说了:计划不如变化,台积电的16nm FinFET工艺虽然速度很快,但还是无法满足NVIDIA的进度要求,只能退而求其次,先用20nm的顶一阵子,相当于临时加了一步棋(要说这代号也取 得很妙),这样时间上自然很紧迫,照搬公版架构就在情理之中了。
按照目前的迹象,Tegra X1应该会只有这一个版本,更美好的事情得等明年。

具体来说,Tegra X1 A57核心搭配了2MB共享二级缓存,每个核心还有48KB一级指令缓存、32KB一级数据缓存,A53核心则共享512KB二级缓存,同时每个核心有32KB一级指令缓存、32KB一级数据缓存。
不过,NVIDIA并没有使用ARM big.LITTLE双架构体系、CCI-400互连总线,而是自己设计了互连总线,还让全部八个核心可以同时运行,系统和应用可以随意调用。
而且,该系统是缓存一致性的,所以不会像类似方案那样损失功耗和性能。
NVIDIA宣称,Tegra X1的能耗比与三星Exynos 7410是齐平的,同等功耗下性能高出40%,同等性能下功耗少50%。——两家都是20nm。

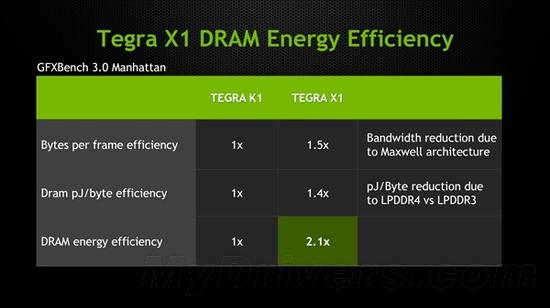
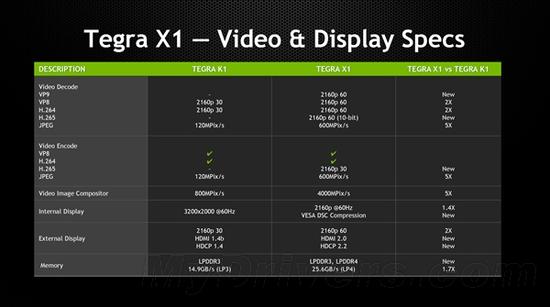
内存支持从LPDDR3升级为LPDDR4,位宽仍然是64-bit,峰值带宽从14.9GB/s增至25.6GB/s,能效也提升了大约40%。
最大内部分辨率也从3200×2000@60Hz增强到了3840×2160@60Hz,并支持VESA显示流压缩。
外部显示方面支持HDMI 2.0、HDCP 2.2,意味着可以搞定4K@60Hz,而上代只有4K@30Hz。
ISP JPEG编码解码速度加快了4倍,同时新增4K@60Hz H.265(10-bit)、VP9解码,但是编码仅支持4K@30Hz H.265。
H.264、VP8解码也都提升到了4K@60Hz。
哦对了,存储支持eMMC 5.1。
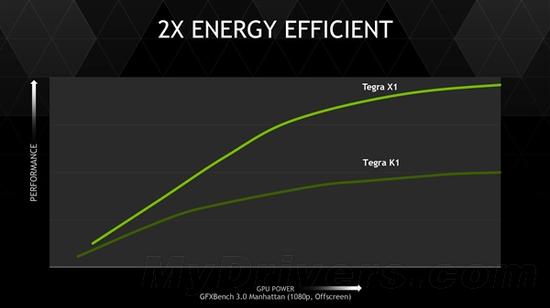
最后的最后,功耗。这是一个很敏感的问题,NVIDIA乃至几乎所有厂商历代都在刻意回避,从不公布具体的功耗指标。这一次NVIDIA也只是说能效比上代提高了一倍。
据说Tegra X1现场展示的需要大约10W,其中GPU非常低,电老虎还是CPU部分。