
摘 要:为从企业生产线上XML半结构化数据中抽取富有意义数据,分析了XML半结构化数据和关系数据库中结构化数据特点,以及XML半结构化数据在关系数据库中的存储方法。针对实际应用,提出采用扩展哈弗曼前缀编码方法,对XML文档树进行唯一编码,实现XML文档与关系数据库映射,同时给出最长前缀匹配策略,支持数据查询,以提高查询效率。
关键词:XML;关系数据库;哈弗曼前缀编码;匹配策略;模型映射
互联网的迅速发展,使得网上数据不断增加,这些数据形式不统一,其数据结构的组织方式也各不相同,促使XML半结构化数据成为互联网上数据交换或数据浏览的中间媒介,其无模式及自描述的特点适于描述网上数据,它的出现推动了互联网在电子商务和企业生产线等多方面的应用。但要想对这种半结构化数据进行有效地管理十分困难,传统的DBMS主要用于管理结构化数据,半结构化数据与传统的DBMS管理的数据的模式大不相同,如何对半结构化数据实施有效的管理成为新的研究领域。而在理论和实践上都非常成熟的关系数据库使用广泛,数据处理能力强,查询性能好,采用关系数据库对XML数据进行存储和操作,将半结构化数据转为结构化数据,通过查询数据库来提取、综合和分析XML数据,充分利用成熟的数据库技术处理XML数据已成为重要手段[1-2]。
互联网的发展也使企业中大量信息资源以XML半结构化数据的形式存在,半结构化数据成为企业决策人员获取、传播和交换信息的重要途径。本文基于一个实际的生产项目,主要对企业生产线中XML半结构化数据资源,采用扩展哈弗曼前缀编码技术转化为在关系数据库中存储,并采用前缀匹配策略实现XML数据查询,抽取富有意义的数据,为管理部门提供完整的决策支持数据,有助于企业决策者实现其目标。
1 XML与关系数据库
XML(Extensible Markup Language)用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型。一个XML文档是由一个根元素和若干个子元素组成,元素用标记来标识和界定,XML可看作是有层次结构的半结构化数据。XML其优势在于可扩展性强,简单易懂,不同平台间的信息交换性好,支持国际化。随着XML技术越来越被人们认识和了解,其在数据传输和数据存储方面的优越性也逐渐被人们重视起来。
关系数据库是为存储和管理结构化数据设计的,采用二维表作为存储数据的模型,二维表由行和列组成,列用于表示组成数据有效信息属性,行用于表示一条由各个字段组成的完整数据记录。表间相关性通过主键—外键来关联。
XML文档是一种典型的半结构化数据[3],它既能表示关系、对象等结构化数据,也能表示Web半结构化数据。具有层次结构的半结构化数据与扁平的二维表关系模型之间存在固有的不匹配性。如果采用关系数据库来存储XML数据,首先要解决如何把XML文档模式映射为关系模式,即两个异构模式之间的模式映射。
2 XML数据与关系数据库转换
2.1 XML数据与关系数据库映射方法
目前,基于关系的XML存储的研究受到国内外研究者的重视,总的来说根据存储时是否使用XML模式(DTD或XML Schema)可以分为结构映射方法和模型映射方法两类。
(1)结构映射是与XML模式(DTD或XML schema)相关[4],即依赖于文档模式的关系存储。这种存储映射策略把XML文档本身看作是数据库中的数据区,DTD或者Schema可以看成是数据模式。依赖于文档模式的关系存储映射就是把DTD或Schema映射为关系数据库中的Schema,然后把XML文档存储到关系数据库中。对XML数据中结构化的信息建模时,采用关系数据库中的主外键连接来映射XML树的父子关系。
(2)模型映射方法维护用来存储XML文档的一个固有的模式[4],其基本的思想是捕捉XML文档的树结构。主要特点是将任何数据都放在有固定关系模式的数据库中,而不考虑XML文档模式(DTD或XML Schema),其本质是存储XML文档本身的结构信息。在模型映射方法中,XML文档被看做由元素和属性等结点组成的有向有序的树或图,关系模式相当于一个模板,XML在关系数据库中的存储按数据库提供的模板来组织数据。
由于模型映射方法与XML模式(DTD或XML schema)无关,而企业生产线上XML数据是一种无模式XML数据,更加符合模型映射的特征。本文采用模型映射方法实现映射转换工作,以便更好地利用关系数据库成熟技术进行数据管理。
2.2 XML文档编码方案
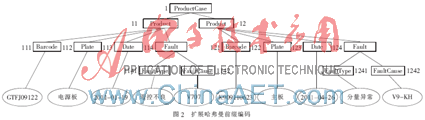
XML文档可以树模型来描述,文档中的元素、属性和值对应树模型中的结点,文档中元素与元素、元素与值对应树模型中的边。对于XML文档树编码方案,主要分为两种:基于区间的编码和基于路径编码。基于区间编码是利用每一个元素在原XML文档中字典顺序位置给每一个结点赋予唯一编码;基于路径编码利用XML文档嵌套关系,给从XML文档根节点开始到达的每一个路径元素结点赋予唯一编码[5]。以上编码方案虽各自有其优点,但不能有效地支持XML数据查询,尤其对于部分匹配复杂查询。因此本文采用扩展的哈弗曼前缀编码方案,在保持XML文档位置关系特性同时,优化XML数据查询,提高查询效率。图1为企业生产线上部分XML文档片段。

哈弗曼编码技术是对二叉树的结点进行编码,即右子树的根结点编码为1,左子树的根结点编码为0,从而确定结点之间的关系。但是XML文档树并不局限于二叉树,其分支是随意的,因此需要对哈弗曼前缀编码技术扩展。
扩展的哈弗曼前缀编码对于元素和属性所对应的内容结点,不对其进行编码;其中任何结点编码都由该节点父结点编码和该结点顺序码组成,并且采用十进制编码方式。对XML文档树从根结点以1开始编码;每个结点的孩子结点按顺序从1,2,3…8,9开始,依次递增、依次类推。这种编码方案不仅能够保存XML文档中节点间包含关系,如双亲/孩子,祖先/后裔,也保存了结点之间的位置关系,如左/右兄弟结点。对于这种编码方法,当判断一个结点v是否为另一个结点u的后裔,只需判断结点编码Node(u)是否是Node(v)的前缀字符,因此,这种编码方式能够有效地支持文档位置关系计算,也能支持包含关系的计算。
具体算法步骤:
(1)输入XML文档生成DOM树;
(2)对根节点进行编码为“1”,根元素入队列;
(3)判断队列是否为空,否则退出循环;
(4)从队列中取结点p,从左到右依次遍历孩子结点;
(5)当访问p的孩子结点非内容结点进行哈弗曼前缀编码,并入队列操作,返回步骤(3)。
当执行算法完毕,XML文档树所有非内容结点编码完成,图2是由图1转换的扩展哈弗曼前缀编码。

2.3 XML数据存储结构
XML文档与关系数据库映射是基于DOM树构建的数据模型,将整个XML文档看作一个树结构DOM树,树中结点即为XML元素、属性和文本等,对DOM树进行遍历,给XML文档结点(元素和属性)赋予惟一扩展哈弗曼前缀编码,所对应的内容结点不对其进行编码。关系模式设置两个基本表,Path表用于存储文档本身的结构信息,Node表存储文档本身的内容信息:
(1)主表Path(Pid,PathInfo,Nodes),保存文档本身结构路径信息,如表1所示。

Pid路径编号,每条路径都有其唯一编号;PathInfo存储是XML文档中的路径标签,从XML文档根结点到每一个元素或属性结点上的所有标签;Nodes记录同一条标签路径对应的所有结点路径。
(2)从表Node(Nid,Pid,Node,Element,Value),保存文档本身内容信息,如表2所示。
Nid是XML文档中结点编号;Pid对应于Path表Pid字段路径编号;Node是XML文档树中结点编码;Element保存XML文档中结点的元素名或属性;Value保存XML文档中叶子属性结点的内容值,如果为非叶子结点的话,则相应的Value值为null。
3 查询过程优化
基于关系存储的XML查询最终都要将XML查询转化为SQL查询,由于Path表中记录数变化不大,而Node表保存每个结点内容信息,企业生产线上XML文档资源很多,导致Node表记录冗长。为提高查询效率,首先在Node表Pid字段上建立索引,并在查询时使用最长前缀匹配方法,即首先将复杂查询分解为限制分支子查询和主子查询,并分别得到其查询编码结果集,使用限制分支子查询得到编码同主子查询得到编码集进行比较,仅保留与限制分支子查询拥有公共前缀编码最长的结点,这样可以得到符合查询的目标编码集。
为获取拥有最长公共前缀编码集,在SQL SERVER中定义标量值函数:CheckString(@Sql nvarchar(100),@Str nvarchar(2),@Split nvarchar(30))此函数是获取拥有最长公共前缀目标编码集的重要函数,其返回值是以逗号分隔的编码集字符串;并定义fn_getArray(@inStr1 nvarchar(100),@inStr2 nvarchar(100))是获取两字符串公共前缀标量值函数,其返回值是公共前缀;定义fn_Split(@Sql nvarchar(100),@Str nvarchar(2))是按照@Str分解字符串,返回值是分解后的Table类型虚拟表。
针对XML数据查询有很多种查询语言,XML查询核心是XPath路径表达式查询,按照查询过程的复杂程度,针对查询路径表达式,可以分为三类[6]:
查询1:简单查询
只含有双亲/子女关系或祖先/后裔关系的路径查询,如:/productCase/Product/Plate,就是按照路径选出相应信息,对应SQL查询:
SELECT B.Nid,B.Value FROM Path as A,Node as B
WHERE A.PathInfo like‘/productCase/Product/Plate’and A.Pid=B.Pid
查询2:分支查询
带有分支谓词的路径查询,如://Fault[/FaultType=‘遥控不良’]/FaultCause
在分支谓词出现的地方将表达式拆分为两个子查询Q1(限制分支查询)://Fault/FaultType=‘遥控不良’和Q2(主查询)://Fault/FaultCause,执行Q1得到限制分支结点{1141}和主结点集{1142,1242},利用限制分支结点对主结点集作最长公共前缀匹配,得到拥有最长前缀编码目标结点{1142},得其内容信息{V707},对应的SQL查询:
SELECT A.Short,B.Value
FROM(SELECT Short FROM dbo.[fn_Split](
(SELECT dbo.[CheckString](T.nos,‘,’,S.no)
FROM(SELECT Path.Nodes as nos FROM Path
WHERE Path.PathInfo like‘%/Fault/FaultCause’)as T,
(SELECT Path.Nodes as no FROM Path,Node
WHERE Path.PathInfo like‘%/Fault/FaultType’AND Node.Value=‘遥控不良’
AND Path.Pid= Node.Pid)as S),‘,’))as A
Node as B WHERE A.Short=B.Node
查询3:通配符查询
包含通配符的路径查询,如:/ProductCase/*/FaultType
在通配符出现的地方将表达式拆分为两个子查询,Q1(限制分支查询):/ProductCase和Q2(主查询):/ProductCase//FaultType,执行Q1得到编码{1},执行Q2得到编码集{1141,1241},这两个编码都是拥有最长前缀编码的结点,因此目标结点是{1141,1241},可得其内容信息{‘遥控不良’,‘分量异常’}对应的SQL查询:
SELECT A.Short,B.Value
FROM(SELECT Short FROM dbo.[fn_Split](
(SELECT dbo.[CheckString](T.nos,’,’,S.no)
FROM(SELECT Path.Nodes as nos FROM Path
WHERE Path.PathInfo like‘/ProductCase%/FaultType’)as T,
(SELECT Path.Nodes as no FROM Path
WHERE Path.PathInfo like‘/ProductCase’)as S),‘,’))as A,
Node as B WHERE A.Short=B.Node
三类查询中,简单查询不涉及使用最长前缀匹配策略;而分支查询、通配符查询时需进行子查询分解,再用最长前缀匹配策略进行查询优化,此时,查询效率要优于常采用的XRel[7]方法。
随着互联网发展,XML正发挥着越来越重要的作用,使用关系数据库的成熟技术来处理XML文档成为研究的热点。由于XML半结构化数据本身特征与关系数据库中结构化数据具有不匹配性,如何解决XML数据到关系数据库映射是重点。本文使用扩展哈弗曼前缀编码的模型映射方法,实现XML数据与关系数据库的映射,这种方法很好地保存XML文档中结点间位置关系,采用最长前缀匹配策略,更好地支持数据查询策略,提高了查询效率。
本文的研究实验基于特定的项目所涉及的数据,因此难免有一定的局限性,对于推广应用还需进一步研究。
参考文献
[1] 孟小峰.XML数据管理概念与技术[M].北京:清华大学出版社,2009.
[2] 吴洁.XML应用教程[M].北京:清华大学出版社,2007.
[3] 潘顺,金远平.半结构化数据到结构化数据的模式抽取[J].计算机工程,2002(5):55-57.
[4] 付灵丽.XML与关系数据库实现转换初探[J].河北工业大学成人教育学报,2007(1):33-36.
[5] 谢桂芳.XML文档编码方案研究[J].科学技术与工程,2009(5):1294-1297.
[6] 王燕丽.基于XML的半结构化数据存储研究[D].山东:山东科技大学,2008.
[7] YOSHIKAWA M, SHIMURA T, UEMURA S. Xrel: A Path-Based approach to storage and retrieval of XML documents using relational database[C]. ACM TOIT,1(1),2001.