
引 言
图像的编解码技术是多媒体技术的关键,H.264/AVC是国际上最先进的视频压缩技术,其主要特点是采用小尺寸整数余弦变换、1/4像素的运动估计精度、多参考帧预测,基于上下文可变长度编码和环路内去块效应滤波器等技术。由于去块效应滤波器大约占整个解码器1/3的运算量,因此该部分的设计成为整个解码器设计的瓶颈,在此研究了一种新颖的环路内去块效应滤波器设计。设计中采用5阶流水线的去块效应模块,利用混合滤波顺序与打乱的存储更新机制的方法提高了流水线畅顺性,滤波一个16×16大小的宏块仅需要198个时钟周期。
1 H.264/AVC的去块效应
在基于块的视频编码方法中,各个块的编解码是互相独立的,由于预测、补偿、变化、量化等引起块与块之间的边界处会产生不连续,因此新版H.264/AVC标准采用了环路内去块滤波器来解决每个16×16宏块重建后的边界扭曲问题。去块效应滤波有两种方法:后处理去块效应滤波;环路内去块效应滤波。H.264/AVC采用环路内去块效应滤波(见图1),即滤波后的帧作为后面预测的参考帧。与之前的H.263或MPEG的滤波器相比较,新版H.264标准采用的滤波器基于更小的4×4的基本宏块,基本宏块的边界根据片级/宏块级的特性与根据像素穿过滤波边界的渐变度,对需要滤波的宏块边界进行有条件的滤波。重建帧的每个像素都需要从外部存储器中重调出来以进行滤波处理或作为相邻像素来判断当前像素是否需要进行滤波。显然,这些操作需要消耗巨大的存储器带宽,对像素值进行修改。
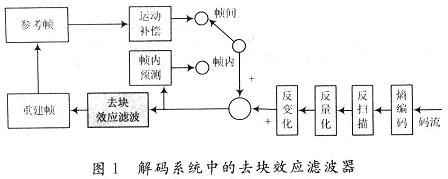
本文设计的去块效应滤波模块采用流水线技术来提高系统吞吐量。理想流水线的高效率实现基于相邻的滤波操作没有数据性。文献[3,4]采用了非流水线的架构,因此无法提高系统的吞吐量。而对于流水线架构,如若不优化滤波顺序与存储器访问次序,则所产生的数据与结构冒险也将大大降低流水线的效率。有人使用双端口的片上SRAM来减少片外存储器的带宽,增加了系统的吞吐量,但是双端口存储器面积较大且增加功耗。与流水线的滤波器相比,非流水线滤波器的操作(包括条件判断、查表、像素计算等)是顺序化的,即每个时钟仅处理一个操作类型,因此它所能达到的最大系统频率要低很多。
采用不同的边界滤波顺序,会大大的影响去块效应滤波器的性能。在H.264/AVC标准中,每个宏块的滤波顺序得到了描述,只要保持滤波数据依赖性,H.264/AVC标准所描述的滤波顺序可以被改进。其滤波顺序包括两类:顺序滤波和混合滤波。但是其滤波顺序以及相应的存储更新机制都是针对非流水线结构的,因此如果直接将之应用于本文的流水线设计,就有可能引发严重的竞争与冒险从而降低流水线的性能。
2 去块效应滤波器的存储管理与滤波算法
H.264/AvC标准基于4×4宏块作为滤波的基本宏块,它有5种滤波强度,分别是Bs=0,1,2,3,4。滤波方式分为强滤波、标准滤波和直通3种方式,其中强滤波影响边界两边的共6个像素,标准滤波影响边界两边的共4个像素,直通方式不修改边界两侧的像素。H.264/AVC标准规定先对垂直边界进行滤波,然后再对水平边界进行滤波,只有对垂直与水平边界全部滤波完成后,才可以对下一个宏块进行滤波。同一个宏块中,先对亮度部分进行滤波,再对色度部分进行滤波;色度部分滤波时,先对C6部分进行滤波,再对Cr部分进行滤波,对整个16×16宏块的滤波顺序如图2所示。
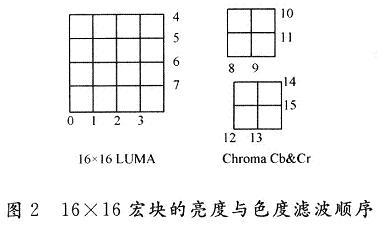
(1)边界滤波强度与像素滤波的存储器
按照H.264/AVC的标准,需要对被滤波的边界两侧的像素进行有条件的滤波。该条件决定于边界强度BS与像素穿越边界的倾斜度。边界强度BS:0,1,2,3或4,在进行滤波之前被赋给相应的边界。BS=4表示强滤波,BS=0表示不需要进行滤波,即直通方式;否则,BS=1,2,3表示中等强度的滤波,色度部分边界的滤波强度与对应亮度部分是相同的。滤波每条水平或垂直边界需要被提供边界两边的8个像素,p0~p3&q0~q3;需要更新的像素共6个或4个:p0~p2&q0~q2或声p0,p1&q0,q1。
对一个16×16宏块进行滤波需要提供左边相邻像素、右边相邻像素和本宏块的像素。对于宏块边界,比如最左边界与最右边界而言,p0~p3与q0~q3来自不同的模块(即分别来自相邻宏块的像素与本宏块的像素);对于非16×16宏块的边界滤波,像素p0~p3与q0~q3均来自16×16宏块本身,因此至少需要4个存储单元:左相邻像素存储单元、上相邻像素存储单元、本身模块的像素存储单元和转换缓冲单元,每个存储单元的带宽是32位。
当滤波从垂直边界向水平边界变换时,为了方便滤波过程中的存储器访问,这里利用额外的转换缓冲器BUF0~BUF3来缓存中间滤波数据,采用转换缓冲器后获取一行或一列像素的值(即p0~p3&q0~q3)只需要1个时钟周期,否则需要4个时钟周期。
(2)滤波算法
环路滤波的基本思想是:判断该边界是图像的真实边界还是编码所形成的块效应边界;对真实边界不滤波,对伪边界根据像素穿越边界的渐变度和编码方式进行滤波;根据滤波强度,选择不同的滤波系数对边界两侧像素进行滤波操作。滤波强度Bs=0的边界将不会进行滤波,而滤波强度Bs不为0的边界,依赖于获取的量化参数α与β,进行阈值判断,对邻近的像素进行有条件的滤波。当滤波强度Bs不是0,并且下面3个条件成立时,才对邻近像素进行滤波。
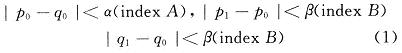
直接计算α,β是非常困难,而且消耗了很多硬件资源,因此通过查找表(LUT)获取α,β的操作。像素的计算可以被分成下述两种类型:
(1)Bs=4
如果以下的两个条件成立,一个非常强的4抽头或5抽头滤波器将被用来对邻近像素进行滤波,修改像素p0,p1,p2。
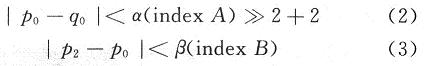
否则,若式(2)中有一个不成立,将不会对p1与p2进行滤波,只会对p0进行弱强度的滤波。对于色度部分边界的滤波,如果式(2)成立,只会对p0与q0进行滤波。
(2)Bs=1~3
亮度像素p0与q0的计算如下:
![]()
而d_0是在裁减操作中被定义的:
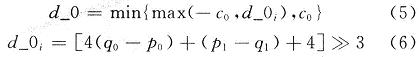
式中:c0来自于c1,而c1是通过查找两维的LUT表获取的。
像素p1仅在式(3)成立的时候进行修改,同p0与q0修改的方式相同;而像素p2与q2对于滤波强度Bs不为4的情况下,不进行滤波。在色度分量进行滤波时,只有对p0与q0进行滤波,滤波的方式与亮度滤波的方式相同。
3 流水线滤波架构
3.1 流水线分析
流水线技术适合于连续的批处理任务,当一个N阶流水线被灌满以后,系统在一个周期内可以并行处理N个任务,由此提高了整组任务的处理速度并增大了系统吞吐能力。如果相邻的滤波操作没有数据竞争,并且所有的阶段都被很好地进行了平衡,则滤波过程能够被进行流水线操作化并可将速度提高N倍数。然而,如若存在竞争与冒险问题,则无法实现。此时的主要任务是如何均衡流水线的各个阶段,如何把总的操作尽可能平均的分配给不同的流水线阶段,如何避免或消除竞争与冒险,以便获得一个比较平衡畅顺的流水线架构。按照去块效应滤波器模块的实现算法,大多数的关键路径位于以下操作中。
(1)查找表操作:取得α,β,c1参数。α,β参数均需在查找表操作之前进行基于量化参数与片级偏移参数的计算中使用。当Bs=1,2,3时,为获取c1进行LUT操作,该操作比获取α,β的LUT操作大3倍。
(2)当Bs=4时,需用4或5抽头的滤波器进行滤波,原来的p,q像素值需要进行移位、相加等操作,以得到最后的结果。
3.2 流水线架构
基于上述分析,这里提出了5阶流水线以提高吞吐量,见图3。由于整个任务被分配到不同的阶段实现,降低滤波的平均时间。
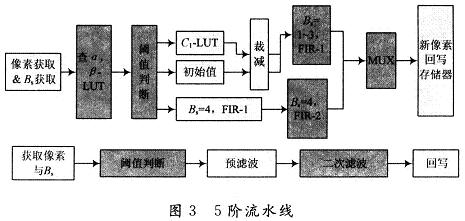
4 阶流水线每个阶段的任务
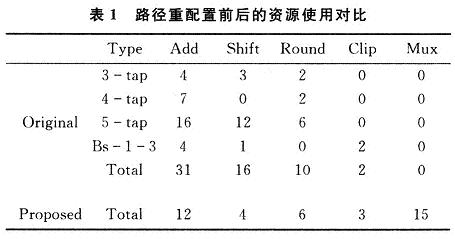
阶流水线每个阶段的任务为:获取像素与滤波强度;阈值判断;预滤波;二次滤波;回写。操作类型转换与可重新配置路径设计:首先进行操作类型的变换,使用加法与移位操作硬件替换了原来所有的乘法与除法硬件。当Bs=4时,滤波被3,4,5抽头的滤波器执行,尽管应用不同抽头数目的滤波器,仍考虑硬件复用以及输入数据路径重新配置。由于设计中的表达式采用两输入加法,因而可以公用加法的中间结果。此外,通过重新配置在不同滤波抽头系数时的加法器的输入,达到共享资源的目的。同理,当Bs=1,2,3时,通过输入路径的重新配置,同样达到共享加法与减法器,达到共享资源的目的,资源使用前后对比见表1。
5 流水线竞争与混合滤波顺序
5.1 流水线竞争的原因
(1)数据竞争:当目的结果需要用作源操作数时;
(2)结构竞争:由于有限的存储器带宽,大量而频繁的像素访问需要以及存储器的低效率管理而引起;
(3)控制竞争:相邻边界的滤波是相对独立的,当一条边界进入它的流水线阶段时,它不能够停止,直到它的第5阶段新像素值回写存储器操作结束。控制竞争,由于分支语句或延迟等待引起的。
5.2 一种新颖的混合滤波顺序
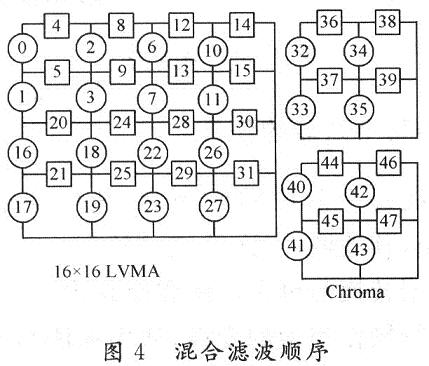
传统的设计按照H.264/AVC标准使用了基本的顺序滤波,没有考虑到相邻滤波边界的数据重用与数据相互依赖性以及存储器的读与写访问延时,因此这里提出了新颖的滤波方法。新颖的滤波顺序仍然遵守先左后右,先上后下的原则,但是考虑了相邻边界的数据依赖性与重用性,解决了数据冒险与结构冒险问题,避免了流水线的延迟。滤波包括亮度部分与色度部分,共48条边界,滤波顺序按照如图4所示的从小到大的数字进行。
5.3 新颖的存储更新策略
考虑到外部存储器的带宽是32位的,为了配合这里提出的边界滤波顺序,避免由于存储器的带宽限制而引起的结构竞争从而导致流水线出现延迟,这里提出了新颖的存储器更新机制,即给不同的4×4宏块分配不同的时隙进行像素回写。
去块效应模块被分配在整个解码模块的最后一步实现,而其它的重建步骤、像帧内滤波模块、帧间滤波模块均以4×4宏块为基本单位来进行流水线处理,但是由于去块效应滤波模块中不同边界之间的数据依赖关系,因而它是以整个16×16宏块为基本单位进行滤波的。此外,只有整个16×16宏块的像素重建完毕之后.才可以进行该宏块的滤波,因而使用了2个SRAM,一个为像素重建提供像素;另一个为像素滤波提供像素,当一个宏块被处理完毕,两个SRAM交换角色,这样避免在两个SRAM之间传递数据导致的时间与功耗开销。使用仿真工具对整个去块效应顶层模块DF_top进行了仿真,仿真部分结果如图5所示。

6 结 语
使用硬件描述语言完成了设计,并在FPGA平台上得到验证。设计采用流水线技术,混合滤波方法,配合新颖的存储器更新机制等方案,实时滤波频率上限约为200 MHz,吞吐量为滤波每个16×16宏块需要198个时钟周期。使用HJTC,CMOS工艺,使用Syn-opsys Co.的DC工具进行综合,时序分析以及功耗分析,结论是时序满足收敛要求,并且完成单个宏块的滤波消耗的能量大约为2μW,功耗得到了很大的降低。