
1引言
本文给出了一种可用于32位以上CPU执行单元的移位寄存器电路,并针对CISC指令集INTELX86进行了优化(由于RISC指令集中移位类指令实现比较简单,故没有在文中讨论);采用指令预处理的技术和通过冗余位,能很方便的实现带进位标志CF移位和设置CF位,并使得每条移位指令的平均执行速度为两个指令周期。它有效地提高了CPU对移位类指令的执行性能,并且作为一个基本的内核单元能很方便地移植到不同指令集(RISC或CISC)的CPU设计之中。
232位CPU中执行单元总体结构
我们所设计的32位CPU的执行部分采用双总线结构,数据总线(Abus,Bbus)的宽度是32位。由于移位类指令如果用ALU进行实现的话,必然会耗费太多的CPU周期,为实现在一个指令周期内对32位数据进行任意位的移位操作,因此有必要在执行单元中设计专用硬件移位寄存器,在执行移位类指令时由它进行32位数据的移位。
图1给出了32位CPU执行单元总体结构数据流结构简图,并省略了所有控制信号。图中Abus为双向32数据总线,Bbus为单向32位数据总线。由于考虑到要实现INTELX86系列所有的移位类指令(RCR,RCL,ROR,ROL等),所以移位寄存器在设计时采用双输入端,即实际该移位寄存器最大能实现64位移位。通过特殊的指令预设置方法,并通过增加冗余位实现标志位的设置。

3移位寄存器单元的设计
3.1矩阵移位器和树状移位器
在CPU中移位寄存器单元的设计一般采用的是矩阵结构和树状结构的移位器。
3.1.1矩阵结构(MatrixStyle)移位器
它的结构为一传输门组成的阵列。行数等于操作数据宽度,列数等于最多能移位数如图2所示(以4位举例)。
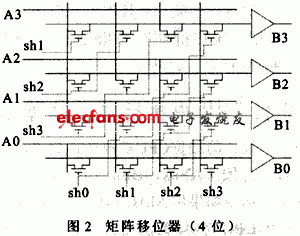
其中A3~A0是4位数据输入线,sh3~sh0是4根控制信号线。每次进行N位移位操作,对应的shN为高,其它控制信号为低。
这种结构的优点是:(1)数据传输的速度快,每个信号到达输出端只经过了一级传输,不受移位器位数限制;(2)版图很规整。缺点是:(1)每根控制信号的负载太大,如32位移位器,每根信号线(sh0,sh1,……sh31)都要驱动32个开关管;(2)所需晶体管数目太多,如n位移位器所需晶体管数为2×n×n=2n2(传输门部分采用CMOS实现),所带来的功耗和芯片面积也会增加;(3)每一移位操作只需一根控制线为1,所以需辅以额外的译码单元。
3.1.2树状结构(TreeStyle)移位器
这种结构M位移位器所需的级数是log2M每一级都由两根信号线(shn和shn#)控制数据的传输,数据在第i级要么移动2i位或者不移动。树状移位器如图3所示。
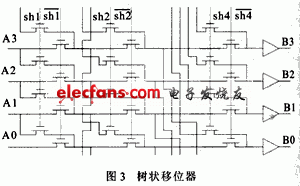
这种结构的优点是:(1)晶体管数目少,n位移器所需晶体管数目为2×n×logn(传输门部分采用CMOS实现),版图面积小于矩阵移位器;(2)控制信号shN~sh0本身就是二进制表示,不需要额外的译码单元。缺点是:数据通路所需经过的开关管数目太多,M位移位器所需的级数是log2M,因此导致延时太大。
3.2矩阵-树状结构移位器
由上面的分析我们可以看出,如果所设计的处理器为16位以下CPU,那其移位器不管采用上述哪种方案都能达到要求,但当数据宽度到32位以上,从功耗,速度及版图面积考虑以上方案的固有缺点就会显得非常突出。在本设计中,移位寄存器的实际输入为64位,为结合矩阵结构的优点(速度快、版图规整)和树状结构的优点(晶体管数目少、译码简单),我们在设计中采用矩阵-树状结构整个移位寄存器的是由双总线输入,即输入64位,表1中列举了不同级别比例的矩阵-树状结构所需晶体管数目(n1为tree的级数,n2为matrix的控制线,n3为matrix中用的晶体管数目)。经过综合考虑,我们采用第2行的矩阵-树状级别比例,即矩阵部分最大能实现8位移位,树状部分最大能实现4位移位。

经过各方面综合考虑,我们所设计的移位寄存器的前级为矩阵结构部分(输入数据为64位,控制信号8位),由这一部分形成一36位的数据送入下一级树状结构(输入数据为36位,控制信号2位)部分再完成剩余的4位移位,形成32位输出数据。结构简图如图4所示。

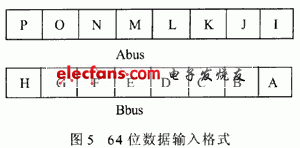
在这个结构中,后级的树状移位器最高实现3位移位。输入的2bit信号为2进制码,这两位由移位计数器sh4~sh0直接将最低两位送入(在后一节将介绍)。前级的矩阵结构完成64位输入36位输出,我们设64位数据输入由Abus,Bbus提供,如图5所示。每一小格代表4位数据。这64位数据送入矩阵移位器后,根据计数器的高三位sh4~sh2进行译码对其进行4,8,12,16,20,24,28,32中的一种移位(对应8bits中的一位为高)。形成36位的数据输出送入下级树状移位器以完成剩余位数的移位。36位数据输出格式如图6所示。其中COUNT表示总共移位数。

4指令的预处理及移位类指令的实现
在我们设计的这片CPU中,需要对INTEL的X86系列移位类指令进行兼容。因此移位寄存器单元需要在周围译码和锁存单元的配合下,要能在一个指令节拍内实现ROL,ROR,RCL,RCR,SHL,SHR,SAR,其中RCL,RCR实现了带标志位C的移位(指令说明见文献[4])。因此需由处理器的控制单元在每类移位指令移位之前进行指令的预处理。
4.1移位寄存器单元总体结构
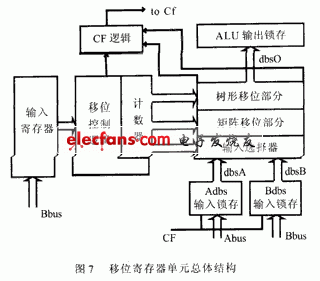
最终设计出的移位寄存器单元总体结构如图7所示,其中其核心部分的矩阵-树状结构的移位寄存器就是使用上一节所描述的结构。记数器中的数据(sh4~sh0)在移位上一拍由Bbus写入,并进行译码,其中低两位(sh1,sh0)直接送树状结构移位部分,高三位(sh4,sh3,sh2)经过译码产生8位控制信号送入矩阵移位部分。Abus和Bbus输入锁存器能锁存32位数据输入,并根据不同指令的要求进行操作,对指令进行预处理。移位结果送ALU输出锁存器,并对CF寄存器进行设置。
4.2指令的预处理
由于要对实现带进位CF的移位并在移位操作后对CF进行设置,在一般情况下这需要CPU的控制单元提供多周期指令节拍来实现。在本设计中,将Abus和Bbus输入锁存器设计为能根据不同的指令实现清0和带CF左移一位或右移一位的操作,以便为移位做好数据上的准备,使输入数据的0~32位移位能在一个指令周期内完成。对不同的指令具体设置情况如图8所示。图中CF表示为进位标志位;len为操作数长度(如32位数据);n为移位数;DATA表示输入锁存输出的数据为操作数据本身;0表示输入锁存输出的数据为0;CF:DATA(-1)表示输入锁存输出的数据为操作数带CF右移一位;DATA(-1):CF表示输入锁存输出的数据为操作数带CF左移一位;SIGN_EXT表示输入锁存输出的数据为操作数带符号扩展。横线下为移位前Abus和Bbus锁存器中数据预处理完后的格式,横线上方位移位完成后数据输出及进位CF所处位置。
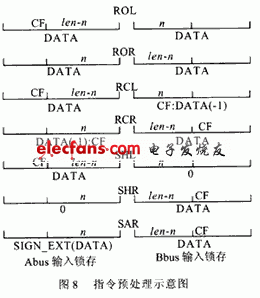
例:RCLAX,CL指令
设AX=0001H,CL="3",CF=1
Abus锁存器输出数据为操作数本0001H;
Bbus锁存器输出的数据为操作数带CF右移一位为1000H;
在输出中,CF在输出结果的最左端为0。
5验证及结论
通过Verilog的行为仿真及starsim的时序仿真显示,性能完全符合要求。对比INTELX86指令集中移位类指令标准执行周期为4~7个机器周期,本设计移位类指令平均执行时间为2个指令周期,因此大大提高了移位类指令执行效率。移位寄存器作为CPU中执行单元的专用硬件,其性能的好坏直接影响到CPU处理移位类指令的速度和效率。本文采用的矩阵-树状结构移位寄存器,配合指令预处理技术,能有效实现32位数据的移位操作,并兼容INTELX86系列的所有移位类指令还可作为通用硬件方便地移植到其他指令级别的CPU设计之中。