
DSP有限的片内存储器容量往往使得设计人员感到捉襟见肘,特别是在数字图像处理、语音处理等应用场合,需要有高速大容量存储空间的强力支持。因此,需要外接存储器来扩展DSP的存储空间。
在基于DSP的嵌入式应用中,存储器系统逐渐成为功耗的主要来源。例如Micron公司的MT48LC2Mx32B2-5芯片,在读写时功耗最大可以到达924 mW,而大部分DSP的内核功耗远远小于这个数值。如TI的TMS320C55x系列的内核功耗仅仅为0.05 mW/MIPS。所以说,优化存储系统的功耗是嵌入式DSP极其重要的设计目标。本文主要以访问外部SDRAM为例来说明降低外部存储系统功耗的设计方法。
1 SDRAM功耗来源
SDRAM内部一般分为多个存储体,通过行、列地址分时复用,系统地址总线对不同存储体内不同页面的具体存储单元进行寻址。SDRAM每个存储体有2个状态,即激活状态和关闭状态。在一次读写访问完毕后,维持存储体激活状态称为开放的页策略(open-page policy),页面寄存器中保存已经打开的行地址,直到它不得不被关闭,比如要执行刷新命令等;访问完毕后关闭存储体称为封闭的页策略(close-page pol-icy)。
为了更好地决定选择哪种策略,需要熟悉SDRAM功耗的特点。SDRAM的功耗主要有3个来源:激活关闭存储体、读写和刷新。在大部分程序中,激活关闭存储体引起的功耗占到访存操作的总功耗的一半以上。图1给出了对同一SDRAM行进行读写时,采用开放的页策略和封闭的页策略的功耗比较(假设激活关闭存储体一次消耗功耗为1),经计算可知,若连续的几个读写操作在同一行,采用开放的页策略可以节省功耗。
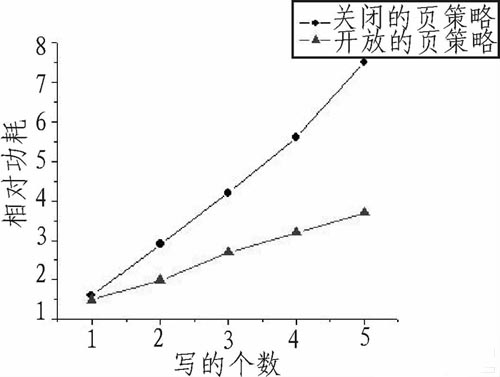
图1 开放的页策略和封闭的页策略的功耗比较
根据上面对SDRAM功耗的特点的分析可知,尽量减少激活/关闭存储体引起的附加功耗开销,是优化SDRAM存储系统功耗的根本,另外不能忽视一直处于激活状态的存储体带来的功耗。
2 访问SDRAM的低功耗优化设计方案
为更好的管理外部SDRAM,大部分嵌入式DSP片上集成和外部存储器的接口EMIF(External Memory Interface),DSP的片内设备通过EMIF访问和管理存储器。由EMIF将对同一行的读写尽量归并到一起进行,减少激活/关闭存储体引起的附加功耗开销。图2为基于总线监测的读写归并设计方案的框图。
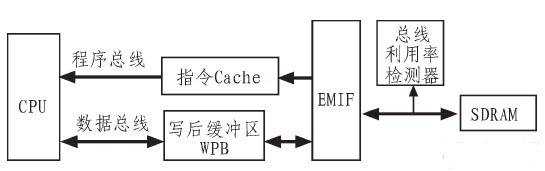
图2 基于总线监测的读写归并设计方案的框图
1)采用块读的方法取指令。加入简化的指令Cache(I-Cache),将对SDRAM的读程序读操作按块进行。只有在Cache错过时,由Cache通过EMIF对SDRAM进行块读,每次读16个字节。
2)加入写后数据缓冲区(WPB,Write PoST Buffer),将数据总线上的请求发往WPB,由WPB对SDRAM进行块写、读写归并。
3)动态监测EMIF总线的利用率,块读和读写归并时采用开放的页策略,当总线利用率较低时,采用封闭的页策略,当总线利用率很低时,将SDRAM进入休眠模式。
3 访问SDRAM的低功耗设计
3.1 采用块读的I-Cache
对于程序总线的读操作,根据程序的局部性原理,下一次要取得指令和当前要取指的指令在空间上很可能相邻,因此对于读程序采用块读的方法,每次读一个块,而不是一个字,并采用开放的页策略,因此对同一行的读写操作不需要额外的激活/关闭操作,可以较快的完成。
当指令放在片外存储器里时,可以将CPU最近使用的指令放在I-Cache中,鉴于改善整个系统的性能和低功耗设计的需求。DSP的I-Cache大小设计为8 KB,包括2块存储器,其结构相同,每一块结构如下:
1)数据队列,每个队列包含256行,每行16个字节。当I-Cache错过时,会采用最近最少使用算法(LRU)替换掉最长时间没有使用的行。
2)行有效位队列,每行有一个行有效位,一旦一行装满数据。就置位该行有效位。
3)标签队列,每一行有一个标签域,表明该行的数据的起始地址。当一行填满,相应的标签将存到该行的标签域中。
如果要取的指令字在I-Cache中(命中),I-Cache会直接将其送给DSP。如果要取的指令字不在I-Cache中(错过),I-Cache会通过EMIF从外部存储器接口读取4个32 b的代码块。一旦这个指令字被读到I-Cache中,就送给CPU。
DSP有限的片内存储器容量往往使得设计人员感到捉襟见肘,特别是在数字图像处理、语音处理等应用场合,需要有高速大容量存储空间的强力支持。因此,需要外接存储器来扩展DSP的存储空间。
在基于DSP的嵌入式应用中,存储器系统逐渐成为功耗的主要来源。例如Micron公司的MT48LC2Mx32B2-5芯片,在读写时功耗最大可以到达924 mW,而大部分DSP的内核功耗远远小于这个数值。如TI的TMS320C55x系列的内核功耗仅仅为0.05 mW/MIPS。所以说,优化存储系统的功耗是嵌入式DSP极其重要的设计目标。本文主要以访问外部SDRAM为例来说明降低外部存储系统功耗的设计方法。
1 SDRAM功耗来源
SDRAM内部一般分为多个存储体,通过行、列地址分时复用,系统地址总线对不同存储体内不同页面的具体存储单元进行寻址。SDRAM每个存储体有2个状态,即激活状态和关闭状态。在一次读写访问完毕后,维持存储体激活状态称为开放的页策略(open-page policy),页面寄存器中保存已经打开的行地址,直到它不得不被关闭,比如要执行刷新命令等;访问完毕后关闭存储体称为封闭的页策略(close-page pol-icy)。
为了更好地决定选择哪种策略,需要熟悉SDRAM功耗的特点。SDRAM的功耗主要有3个来源:激活关闭存储体、读写和刷新。在大部分程序中,激活关闭存储体引起的功耗占到访存操作的总功耗的一半以上。图1给出了对同一SDRAM行进行读写时,采用开放的页策略和封闭的页策略的功耗比较(假设激活关闭存储体一次消耗功耗为1),经计算可知,若连续的几个读写操作在同一行,采用开放的页策略可以节省功耗。
图1 开放的页策略和封闭的页策略的功耗比较
根据上面对SDRAM功耗的特点的分析可知,尽量减少激活/关闭存储体引起的附加功耗开销,是优化SDRAM存储系统功耗的根本,另外不能忽视一直处于激活状态的存储体带来的功耗。
2 访问SDRAM的低功耗优化设计方案
为更好的管理外部SDRAM,大部分嵌入式DSP片上集成和外部存储器的接口EMIF(External Memory Interface),DSP的片内设备通过EMIF访问和管理存储器。由EMIF将对同一行的读写尽量归并到一起进行,减少激活/关闭存储体引起的附加功耗开销。图2为基于总线监测的读写归并设计方案的框图。
图2 基于总线监测的读写归并设计方案的框图
1)采用块读的方法取指令。加入简化的指令Cache(I-Cache),将对SDRAM的读程序读操作按块进行。只有在Cache错过时,由Cache通过EMIF对SDRAM进行块读,每次读16个字节。
2)加入写后数据缓冲区(WPB,Write PoST Buffer),将数据总线上的请求发往WPB,由WPB对SDRAM进行块写、读写归并。
3)动态监测EMIF总线的利用率,块读和读写归并时采用开放的页策略,当总线利用率较低时,采用封闭的页策略,当总线利用率很低时,将SDRAM进入休眠模式。
3 访问SDRAM的低功耗设计
3.1 采用块读的I-Cache
对于程序总线的读操作,根据程序的局部性原理,下一次要取得指令和当前要取指的指令在空间上很可能相邻,因此对于读程序采用块读的方法,每次读一个块,而不是一个字,并采用开放的页策略,因此对同一行的读写操作不需要额外的激活/关闭操作,可以较快的完成。
当指令放在片外存储器里时,可以将CPU最近使用的指令放在I-Cache中,鉴于改善整个系统的性能和低功耗设计的需求。DSP的I-Cache大小设计为8 KB,包括2块存储器,其结构相同,每一块结构如下:
1)数据队列,每个队列包含256行,每行16个字节。当I-Cache错过时,会采用最近最少使用算法(LRU)替换掉最长时间没有使用的行。
2)行有效位队列,每行有一个行有效位,一旦一行装满数据。就置位该行有效位。
3)标签队列,每一行有一个标签域,表明该行的数据的起始地址。当一行填满,相应的标签将存到该行的标签域中。
如果要取的指令字在I-Cache中(命中),I-Cache会直接将其送给DSP。如果要取的指令字不在I-Cache中(错过),I-Cache会通过EMIF从外部存储器接口读取4个32 b的代码块。一旦这个指令字被读到I-Cache中,就送给CPU。
3.2 写后缓冲区的设计
数据在存储器中的存放位置可能不像程序空间那么连续,而且数据空间有读写,对数据空间读写SDRAM进行优化的基本思想是,归并对SDRAM同一行的读写操作。具体来说,包括归并对同一行的多个读操作、归并对同一行的多个写操作,归并对同一行的多个读写操作3种情况,文献提出了这种设计方法,其基本思想是:系统从预取缓冲区(FB,Fetch Buffer)中取数据;写数据时,先写到写归并缓冲区(WCB,Write Combine Buffer);对在FB或WCB中的同一行的读写请求进行归并。但此设计方法是针对有一级Cache的通用微处理器系统,过于复杂,实现代价过高,不适合于本文研究的没有一级数据Cache的DSP,因此这里采用写后缓冲区(Write Post Buffer)的方法,具体设计方法如下:
1)在EMIF中设立一个写后缓冲区,所有对SDRAM的读写请求均送到写后缓冲区,写后缓冲区立即给CPU响应,CPU可以不用等待写操作的结束而继续执行程序。
2)每当写后缓冲区接受到一个新的写请求后,首先判断写后寄存器中是否存在和该写操作在SDRAM同一行的写操作,若有,将这两个写操作归并后同时向SDRAM进行写。
3)当CPU读数据时,首先检查写后缓冲区,若存在要读的数据,直接从写后缓冲区读数据;若不存在,则从写后缓冲区中挑选和当前读操作在同一行的写操作归并后,对SDRAM进行读、写操作。
设计写后缓冲区不仅可以提高程序的执行效率,还可以节省功耗。综合考虑系统的性能与功耗要求,这里DSP写后缓冲区设计为8 KB,采用和I-Cache类似的结构。
3.3 动态监测总线利用率
SDRAM在所有的行都打开,等待读写操作时的功耗是所有行都关闭时的2倍多,因此SDRAM为了低功耗的需要,设计时都加入了休眠模式。当对同一行有大量的读写时,又需要采用开放的页策略,维持这些行打开。考虑到SDRAM的这些特点,单独采用开放的页策略或封闭的页策略是不合适的,需要结合运用。动态监测EMIF总线的利用率,块读、块写和读写归并时采用开放的页策略,当总线利用率较低时,采用封闭的页策略,当总线利用率很低时,将SDRAM进入休眠模式,需要时再澈活。
以MT48LC2M32P2为例进行功耗估算,假设前后两次访问命中同一行的概率是90%,当总线利用率(每个周期内总线被平均利用的次数)高于25%时。采用开放的页策略比采用封闭的页策略节省功耗,当总线利用率在25%~20%之间时,采用两种策略差别不大,维持当前采用的策略,当总线利用率低于20%时,采用封闭的页策略比采用开放的页策略节省功耗,当总线利用率低于10%时,在采用封闭的页策略的同时,每次访问结束后都将SDRAM进入休眠模式,比单纯采用封闭的页策略更节约功耗。
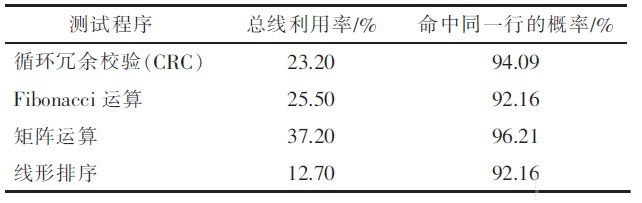
文献统计了通用处理器中不同程序的总线的利用率,如表1所示。可见,对于不同的程序,总线利用率差别较大。根据当前总线的利用率来决定采用何种策略访问SDRAM是比较合适的。
表1
4 优化后的EMIF的性能分析
对采用的总线监测的读写归并方案进行计算,假设前后命中同一行的概率是90%,根据Micron数据手册计算,归并两个写操作功耗减少24%,对不同的总线利用率的计算结果如图3所示。
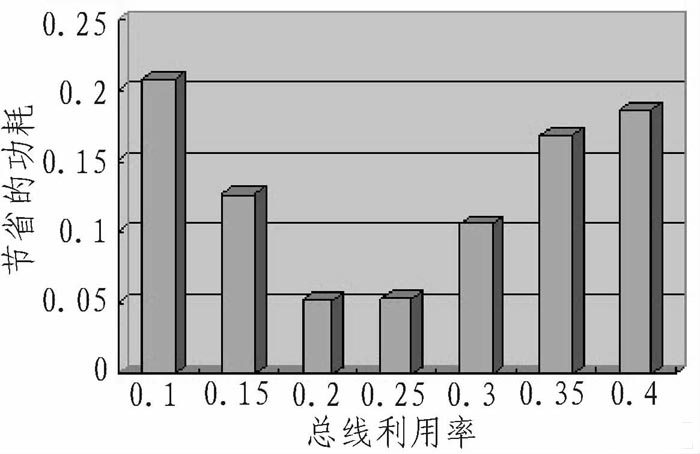
图3 基于总线监测的读写归并方案功耗计算
5 结束语
在基于DSP的嵌入式应用系统中,存储系统的功耗占据系统功耗的大部分。当外部存储器采用SDRAM时,降低SDRAM的换行访问可以节约大量的功耗。本文设计的基于总线监测的读写归并方案,不仅降低了外部存储系统的功耗,而且可以在一定程度上提高存储系统的性能。加入的I-Cache可以使程序总线更快地读指令,加入的写后缓冲区(WPB)可以使CPU不用等待缓慢的外部写操作的结束而直接继续执行指令。