FPGA在深度学习应用中或将取代GPU
0赞 人工智能的兴起触发了市场对 GPU 的大量需求,但 GPU 在 AI 场景中的应用面临使用寿命短、使用成本高等问题。现场可编程门阵列 (FPGA) 这一可以定制化硬件处理器反倒是更好的解决方案。随着可编程性等问题在 FPGA 上的解决,FPGA 将成为市场人工智能应用的选择。
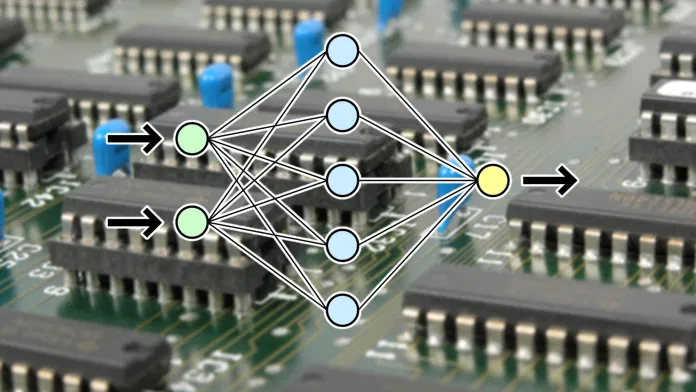
现场可编程门阵列 (FPGA) 解决了 GPU 在运行深度学习模型时面临的许多问题
在过去的十年里,人工智能的再一次兴起使显卡行业受益匪浅。英伟达 (Nvidia) 和 AMD 等公司的股价也大幅上涨,因为事实表明,它们的 GPU 在训练和运行 深度学习模型 方面效果明显。实际上,英伟达也已经对自己的业务进行了转型,之前它是一家纯粹做 GPU 和游戏的公司,现在除了作为一家云 GPU 服务提供商外,英伟达还成立了专业的人工智能研究实验室。
不过,机器学习软件公司 Mipsology 的首席执行官兼联合创始人卢多维奇•拉祖尔 (Ludovic Larzul) 表示,GPU 还存在着一些缺陷,这使其在 AI 应用中面临着一些挑战。
Larzul 表示,想要解决这些问题的解决方案便是实现现场可编程门阵列 (FPGA),这也是他们公司的研究领域。FPGA 是一种处理器,可以在制造后定制,这使得它比一般处理器更高效。但是,很难对 FPGA 进行编程,Larzul 希望通过自己公司开发的新平台解决这个问题。
专业的人工智能硬件已经成为了一个独立的产业,但对于什么是深度学习算法的最佳基础设施,人们仍然没有定论。如果 Mipsology 成功完成了研究实验,许多正受 GPU 折磨的 AI 开发者将从中受益。
GPU 深度学习面临的挑战
三维图形是 GPU 拥有如此大的内存和计算能力的根本原因,它与 深度神经网络 有一个共同之处:都需要进行大量矩阵运算。
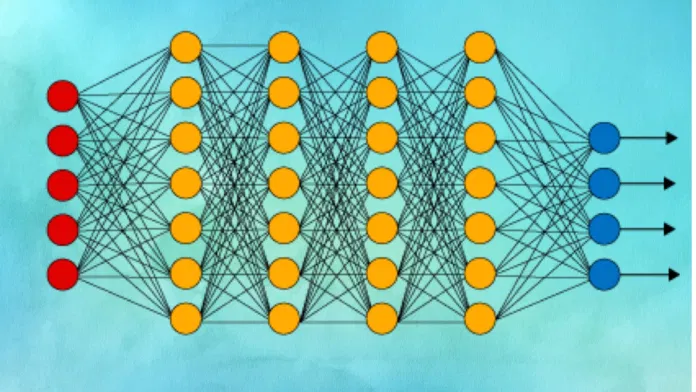
显卡可以并行执行矩阵运算,极大地加快计算速度。图形处理器可以把训练神经网络的时间从几天、几周缩短到几小时、几分钟。
随着图形硬件公司供货的不断增加,GPU 在深度学习中的市场需求还催生了大量公共云服务,这些服务为深度学习项目提供强大的 GPU 虚拟机。
但是显卡也受硬件和环境的限制。Larzul 解释说:“神经网络训练通常是在一个确定的环境中进行的,运行神经网络的系统会在部署中遇到各种限制——这可能会对 GPU 的实际使用造成压力。”
GPU 需要大量的电力,会产生大量的热量,并需要使用风扇冷却。当你在台式工作站、笔记本电脑或机架式服务器上训练神经网络时,这不是什么大问题。但是,许多部署深度学习模型的环境对 GPU 并不友好,比如自动驾驶汽车、工厂、机器人和许多智慧城市环境,在这些环境中硬件必须忍受热、灰尘、湿度、运动和电力限制等环境因素。
Larzul 说:“在一些关键的应用场景中,比如智慧城市的视频监控,要求硬件暴露在对 GPU 有不利影响的环境因素 (比如太阳) 下。“ GPU 受晶体管技术的限制,导致它们在高温下运行时需要及时冷却,而这并不总是可以实现的。要做到这点需要更多的电力、维护成本等。”
使用寿命也是一个问题。一般来说,GPU 的使用 寿命约为 2-5 年,这对那些每隔几年就换一次电脑的玩家来说不是什么大问题。但在其他领域,如汽车行业,需要硬件有更高的耐用性,这就带来了问题。特别是过多的暴露在恶劣的环境中,再加上高强度的使用,GPU 的使用寿命将会更短。
Larzul 说:“从商业可行性方面考虑,自动驾驶汽车等应用可能需要多达 7-10 个 GPU(其中大多数会在不到四年的时间内失效),对于大多数购车者来说,智能或自动驾驶汽车的成本将变得不切实际。”
机器人、医疗保健和安全系统等其他行业也面临着类似的挑战。
FPGA 和深度学习
FPGA 是可定制的硬件设备,可对其组件进行调节,因此可以针对特定类型的架构 (如 卷积神经网络) 进行优化。其可定制性特征降低了对电力的需求,并在运算速度和吞吐量方面提供了更高的性能。它们的使用寿命也更长,大约是 GPU 的 2-5 倍,并且对恶劣环境和其它特殊环境因素有更强的适应性。
有一些公司已经在他们的人工智能产品中使用了 FPGA。微软 就是其中一家,它将基于 FPGA 的机器学习技术作为其 Azure 云服务产品的一部分来提供。
不过 FPGA 的缺陷是难于编程。配置 FPGA 需要具备硬件描述语言 (如 Verilog 或 VHDL) 的知识和专业技能。机器学习程序是用 Python 或 C 等高级语言编写的,将其逻辑转换为 FPGA 指令非常困难。在 FPGA 上运行 TensorFlow、PyTorch、Caffe 和其他框架建模的神经网络通常需要消耗大量的人力时间和精力。
“要对 FPGA 进行编程,你需要组建一支懂得如何开发 FPGA 的硬件工程师团队,并聘请一位了解神经网络的优秀架构师,花费几年时间去开发一个硬件模型,最终编译运行在 FPGA 上,与此同时你还需要处理 FPGA 使用效率和使用频率的问题。“Larzul 说。此外你还需要具备广泛的数学技能,以较低的精度准确地计算模型,并需要一个软件团队将 AI 框架模型映射到硬件架构。
Larzul 的公司 Mipsology 希望通过 Zebra 来弥合这一差距。Zebra 是一种软件平台,开发者可以轻松地将深度学习代码移植到 FPGA 硬件上。
Larzul 说:“我们提供了一个软件抽象层,它隐藏了通常需要高级 FPGA 专业知识的复杂性。”“只需加载 Zebra,输入一个 Linux 命令,Zebra 就可以工作了——它不需要编译,不需要对神经网络进行任何更改,也不需要学习任何新工具。不过你可以保留你的 GPU 用于训练。”
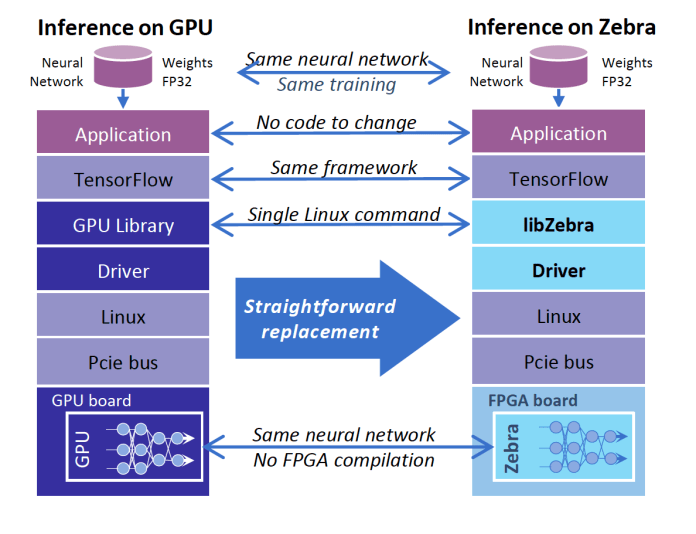
Zebra 提供了将深度学习代码转换为 FPGA 硬件指令的抽象层
AI 硬件前景
Mipsology 的 Zebra 平台是开发者探索在 AI 项目中使用 FPGA 的 众多方案之一。Xilinx 是 FPGA 领域的领导者,已经开发了 Zebra 并将其集成到了电路板中。其他公司,如谷歌和特斯拉,也正积极的为其开发专用的 AI 硬件,用于自己的云产品和边缘计算产品环境中。
神经形态芯片 方面也有着一些发展,这是一种专门为神经网络设计的计算机架构。英特尔在神经形态计算领域处于领先地位,已经开发了几种模型架构,不过该领域仍处于早期发展阶段。
还有专门用于特定应用的集成电路 (ASIC),即专为某一特定人工智能需求制造的芯片。但 ASIC 缺乏 FPGA 的灵活性,无法重新编程。
Larzul 最后说,“我们决定专注于软件业务,探索研究提升神经网络性能和降低延迟的方案。Zebra 运行在 FPGA 上,因此无需更换硬件就可以支持 AI 推理。FPGA 固件的每次刷新都能给我们带来更高的性能提升,这得益于其高效性和较短的开发周期。另外,FPGA 的可选择方案很多,具有很好的市场适应性。”

