片上网络小记(4)
0赞
发表于 2014/4/30 19:38:38
阅读(23159)
各位,最近比较头大的写一个draft,目前已经有了一些进展。所以现在要来进一步的写片上网络小记,把NoC based 的MPSoC继续写完。不过话说回来这个人X日报号召所谓的汉语纯洁性,我这才开篇没有几句话就让汉语不纯洁了。但是为了简洁和方便起见,我还是不得不继续使用这些英文缩写词,各位不要到人X日报那里去举报我。不过话说新华社好像都对人X日报看不过眼了……
上文说到,MPSoC是从板级的嵌入式系统发展而来的。而板级嵌入式系统上面采用多个独立的处理器/子系统相互配合实现一个功能是很正常的。当我们的计算量达到一定的程度的时候,将其扩展成多个处理器/子系统并行的就很正常了。比如类似于早年在雷达信号处理中使用的DSP阵列之类的。
由于这类处理器/子系统通常都是相对独立的完成整个大系统中的某一个模块, 同时整个大系统的工作任务单一而明确。对于这类系统通常都可以抽象出明确的任务图或者是数据流图。
下图就是论文: A Reconfigurable Source-Synchronous On-Chip Network for GALS Many-Core Platforms给出的802.11a基带接收机的数据流图:
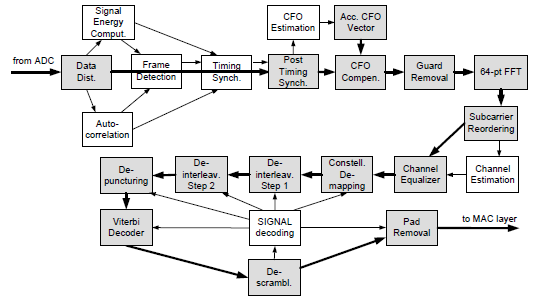
图1.802.11a接收机数据流图
可以看出整个任务就是完成一个802.11a的基带信号处理,整个数据流清晰明确,各个模块自成一体。 图2是这个NoC based 的MPSoC实现框图。这个系统的核心是源同步时钟电路,换言之就是由上一个处理器核输出端口为下一个处理器的输入FIFO提供时钟。这在通常的NoC设计中也是属于常见设计。
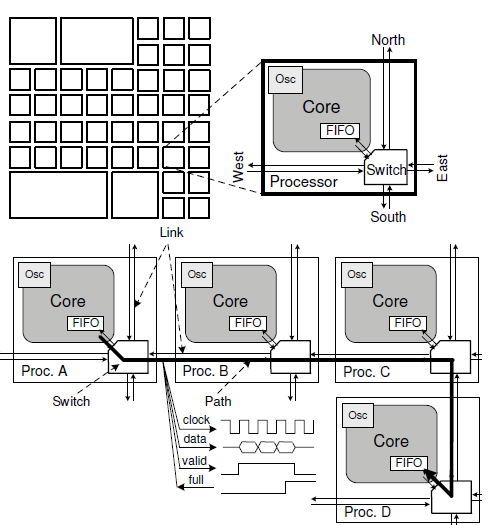
图2 基于源同步时钟GALS多核系统架构
在图2中可以看出每一个单元是独立工作的,消息的传递并非通过外部共享的一个存储器而是依靠处理器之间的FIFO直接传递。这种方式我们可以看到在并行机里面也有类似的结构,这就是MPP:
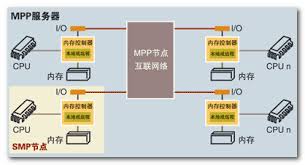
图3 MPP-(Massive Parallel Processing)架构
目前排名靠前的超级计算机基本都采用的是MPP架构, 包括中国的天河系列。在大型机或者通用计算中采用MPP的一大难点是整个消息或者数据的传递过程完全要依靠软件程序来实现,不像SMP或者NUMA那样是不需要程序员去关心底层的消息传递过程。不过好在我们的大多数MPSoC系统其实规模远没有那么大,而且数据流也还真是可以预测或者规划的。
当然,还有另外的一些类似的结构,如图4所示把一些小的PE链接起来的NoC,用来实现粗粒度的可重构系统。
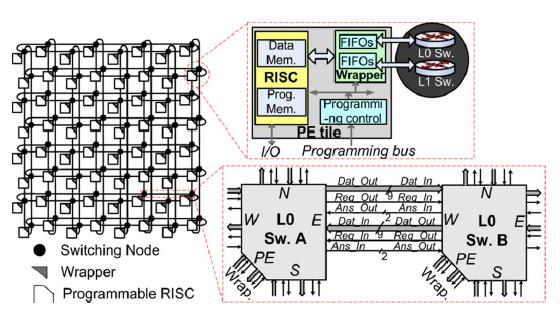
图4 基于NoC的粗粒度可重构系统
不过说起可重构,我要力推的是下面这张图,嵌入了NoC硬核的FPGA。今天刚刚查到计算机体系结构顶级期刊IEEE Micro上的论文
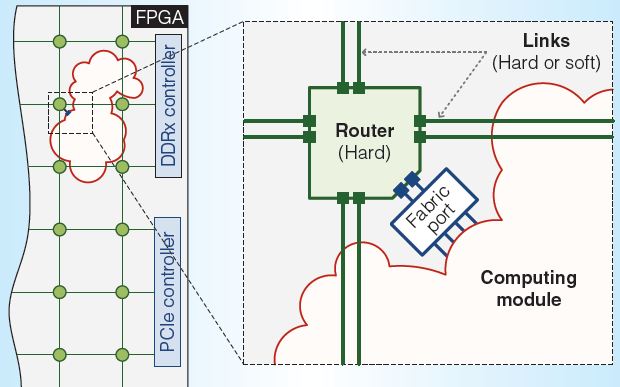
图5 嵌入了NoC硬核的FPGA
嵌入式的router大概相当于9个logic block,目测大小应该和18*18的DSP模块的大小接近。对于FPGA来说这个不算什么开销,但是可以极大的节约FPGA中最大的开销——布线资源。
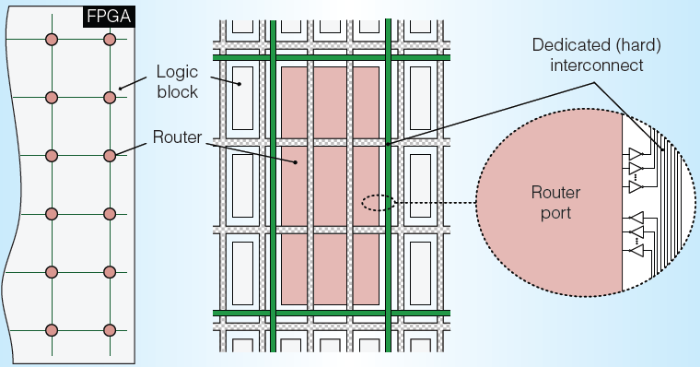
图6 嵌入式Router示意图
我看到这篇论文的时候就觉得这货不会是Altera搞出来的吧。看到最后果然鸣谢了Altera……当看到图5的时候,我突然黯然泪下。那一刻我想起了那天夕阳下的奔跑, 那是我逝去的青春……
上文说到,MPSoC是从板级的嵌入式系统发展而来的。而板级嵌入式系统上面采用多个独立的处理器/子系统相互配合实现一个功能是很正常的。当我们的计算量达到一定的程度的时候,将其扩展成多个处理器/子系统并行的就很正常了。比如类似于早年在雷达信号处理中使用的DSP阵列之类的。
由于这类处理器/子系统通常都是相对独立的完成整个大系统中的某一个模块, 同时整个大系统的工作任务单一而明确。对于这类系统通常都可以抽象出明确的任务图或者是数据流图。
下图就是论文: A Reconfigurable Source-Synchronous On-Chip Network for GALS Many-Core Platforms给出的802.11a基带接收机的数据流图:

图1.802.11a接收机数据流图
可以看出整个任务就是完成一个802.11a的基带信号处理,整个数据流清晰明确,各个模块自成一体。 图2是这个NoC based 的MPSoC实现框图。这个系统的核心是源同步时钟电路,换言之就是由上一个处理器核输出端口为下一个处理器的输入FIFO提供时钟。这在通常的NoC设计中也是属于常见设计。

图2 基于源同步时钟GALS多核系统架构
在图2中可以看出每一个单元是独立工作的,消息的传递并非通过外部共享的一个存储器而是依靠处理器之间的FIFO直接传递。这种方式我们可以看到在并行机里面也有类似的结构,这就是MPP:

图3 MPP-(Massive Parallel Processing)架构
目前排名靠前的超级计算机基本都采用的是MPP架构, 包括中国的天河系列。在大型机或者通用计算中采用MPP的一大难点是整个消息或者数据的传递过程完全要依靠软件程序来实现,不像SMP或者NUMA那样是不需要程序员去关心底层的消息传递过程。不过好在我们的大多数MPSoC系统其实规模远没有那么大,而且数据流也还真是可以预测或者规划的。
当然,还有另外的一些类似的结构,如图4所示把一些小的PE链接起来的NoC,用来实现粗粒度的可重构系统。

图4 基于NoC的粗粒度可重构系统
不过说起可重构,我要力推的是下面这张图,嵌入了NoC硬核的FPGA。今天刚刚查到计算机体系结构顶级期刊IEEE Micro上的论文

图5 嵌入了NoC硬核的FPGA
嵌入式的router大概相当于9个logic block,目测大小应该和18*18的DSP模块的大小接近。对于FPGA来说这个不算什么开销,但是可以极大的节约FPGA中最大的开销——布线资源。

图6 嵌入式Router示意图
我看到这篇论文的时候就觉得这货不会是Altera搞出来的吧。看到最后果然鸣谢了Altera……当看到图5的时候,我突然黯然泪下。那一刻我想起了那天夕阳下的奔跑, 那是我逝去的青春……


