Linux内核实现中断和中断处理(二)
0赞上回说了Linux内核实现中断会把中断分为两部分进行处理,上回讲了上部分,这回讲下部分的设计思路
- 下半部的实现机制
-
- 软中断
- tasklet:是通过软中断实现的,但和软中断有所不同
- 工作队列
讲上面几个实现机制之前先讲一个古老的方法,现在版本的内核虽然已经不再食用了,但是思想还在继续使用
最早的Linux只提供了“bottom half”这种机制实现下半部分,被称为BH,实现简单粗暴,设置一个全局变量(32位整数),表示一个32个节点的链表队列,哪位设置为1证明哪个bottom half就可以执行了。
- 软中断
第一个先将软中断实现下半部分机制,要想将这个机制,必须得先说明软中断的实现方式,软中断实在编译期间静态分配的,kernel/softirq.c中定义了一个包含有32个结构体的数组static struct softirq_action softirq_vec[NR_SOFTIRQS],并且有一个对应的32位整数u32 pending,用来表示每个软中断的状态(不要嫌少,一般根本用不了那么多,一般9个10个就够用了,为什么这么少?很少有用软中断处理下半部分的,能用tasklet的地方绝不会使用软中断)
把软中断放进刚才说的32个长度的结构体数组中就完成了软中断的注册,想要执行软中断必须先标记注册好的软中断,这个过程被称为触发软中断,通常,中断处理程序(就是上半部分)会在返回之前标记它的软中断,所以不必担心,然后在合适的时刻就会执行该软中断
合适的时刻:1.从一个硬件中断代码处返回时;2.在ksoftirqd内核线程中;3.在那些显示检查和执行待处理的软中断的代码中;
不管是上面哪个时刻,软中断最终都是会被执行的,调用do_softirq()该函数会循环遍历(循环检查pending的每一个位,所以循环最多只能执行32次)
- tasklet
因为takslet是使用软中断实现的,所以tasklet本身就是个软中断,我们是通过tasklet来实现下半部的机制的,所以在处理方式上和软中断十分的相似,tasklet由tasklet结构体表示,每一个结构体单独代表一个tasklet,它的定义如下

1 struct tasklet_struct 2 { 3 stauct tasklet_struct *next;//链表中的下一个节点 4 unsigned long state;//tasklet的状态 5 atomic_t count;//引用计数器 6 void (*func)(unsigned long);//tasklet处理函数 7 unsigned long data;//给tasklet处理函数的参数 8 };
其中tasklet的状态一共只有三种:0,TASKLET_STATE_SCHED,TASKLET_STATE_RUN,只能在这三种之间取值,0表示啥也没有等待调度,SCHED表示已经调度,RUN表示该tasklet正在运行。
已经被调度的tasklet结构体存放在两种单处理器数据结构当中,分别是tasklet_vec(普通优先级的tasklet)和tasklet_hi_vec(高优先级的tasklet),几乎没区别,只是优先级不一样,调度的步骤如下
- 检查tasklet的状态是否为TASKLET_STATE_SCHED,如果是,就证明不需要调度了,直接返回
- 调用_tasklet_schedule()函数进行调度
- 保存中断状态,禁止本地中断,防止数据被其他中断拿去更改
- 头插加入链表,就刚才说的那两个优先级不同的链表
- 唤起tasklet中断(封装好的软中断)
- 恢复中断并返
运行的步骤如下:
- 禁止中断,检测两个链表里面有没有东西
- 把当前处理器的该链表设置为NULL(意思就是我要把链表里的东西全弄完,先置成NULL)
- 允许相应中断
- 循环遍历tasklet链表上的每一个节点
- 如果是多处理器系统,查看节点状态如果是RUN就证明在其他处理器上运行中,直接跳到下一个节点(因为同一时间里,相同类型的tasklet只有一个能执行)
- 如果当前节点的状态不是RUN,就设置成RUN,以防其他处理器调用
- 检查count是不是0(看看别人是否正在占用)如果不是0则被禁止,跳到下一个挂起的tasklet去
- 安全确保,开始执行
- 一直循环,直到没有tasklet了(因为我们把链表置为NULL了,必须把拿出来的东西处理完)
其实tasklet给人的感觉就是一个对软中断的封装的简单接口而已。。
每个处理器都有一组辅助处理软中断(当然也就包括tasklet)的内核线程,那么什么时候执行这些软中断呢,上面在软中断部分也阐述了,但是这样有个问题,那就是软中断如果继续调软中断,就会不停的执行软中断。。这样在处理器负载很严重的时候就不太好了,会导致用户空间进程饥饿,还有一种方案,那就是并不立即处理软中断,而是等待一段时间,但是在处理器比较闲的时候这么做很显然不太好,因为完全可以立即执行你却让处理器闲着。作为改进,当大量软中断出现的时候,内核会唤醒一组内核线程来处理这些负载,关键来了,这些带着软中断的线程的优先级会被设置到最低的优先级上(nice值取最高为19),这样的会在处理器比较忙的时候,这些软中断不会跟用户空间进程争夺处理器资源,而且最终一定会被执行,处理器空闲的时候也可以直接得到运行。
- 工作队列
工作队列是另外一种比较新的将工作推后的形式,和之前的两种处理方式不同,它会把工作交给一个内核线程去执行,这就意!味!着!是由进程上下文来处理了!就可以睡眠了!!(中断是不允许睡眠的)所以很简单就可以在这两种方法之间做出选择。
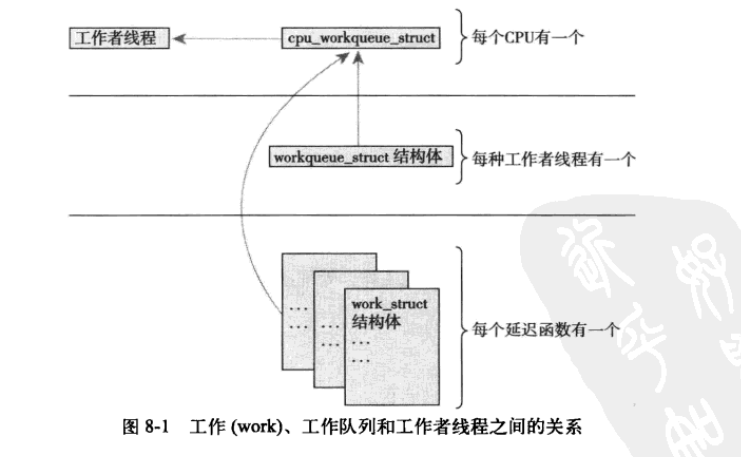
每一个处理器都有一个对应的工作者线程
1 struct workqueue_struct 2 { 3 struct cpu_work_queue_struct cpu_wq[NR_CPUS]; 4 struct list_head list; 5 const char *name; 6 int sinqlethread; 7 int freezeable; 8 int rt; 9 };

1 struct cpu_workqueue_struct 2 { 3 spinlck_t lock;//锁保护这种结构 4 struct list_head worklist;//工作列表 5 wait_queue_head_t more_work; 6 struct work_struct *current_struct; 7 struct workqueue_struct *wq;//关联工作队列结构 8 task_t *thread;//关联线程 9 };
表示工作的数据结构
1 struct work_struct 2 { 3 atomic_long_t data; 4 struct list_head entry; 5 work_func_t func; 6 };
这些工作的结构体被连城链表,当链表上的所有工作都做完了之后,线程就会休眠
实现方式也很简单,
- 线程首先把自己设置为休眠状态(只是设置,并没有立即进入休眠)并把自己加入等待队列
- 如果工作链表是空的,就用schedule()调度函数进入睡眠状态
- 如果链表中有对象,线程就不会睡眠了,就把自己的状态改为TASK_RUNNING,然后从等待队列中出来
- 如果链表非空,执行那些被退后的下半部分应该干的工作(就是循环一直找。。。)
来个结构图
- 下半部机制的选择
这三种看上去都不错,那么应该怎么选择呢
如果你对共享有很高的要求,虽然比较麻烦,但还是使用软中断吧,因为可以各种操作(虽然保障这些很麻烦)
如果你不是对共享有那么高的要求,推荐使用tasklet,因为两种同类型的tasklet不能同时并行
如果你想在进程上下文中解决下半部分的问题,使用工作队列吧,当然如果你想睡眠,你也没得选了
* 全剧终*

